While Large Language Model (LLM) agents demonstrate proficiency in static benchmarks, their deployment in real-world scenarios is hindered by the dynamic nature of user queries, tool sets, and interaction dynamics. To address this generalization gap, we formalize OpenAgent (Tool-Use Agent in Open-World), a problem setting characterized by distributional shifts across query, action, observation, and domain dimensions.
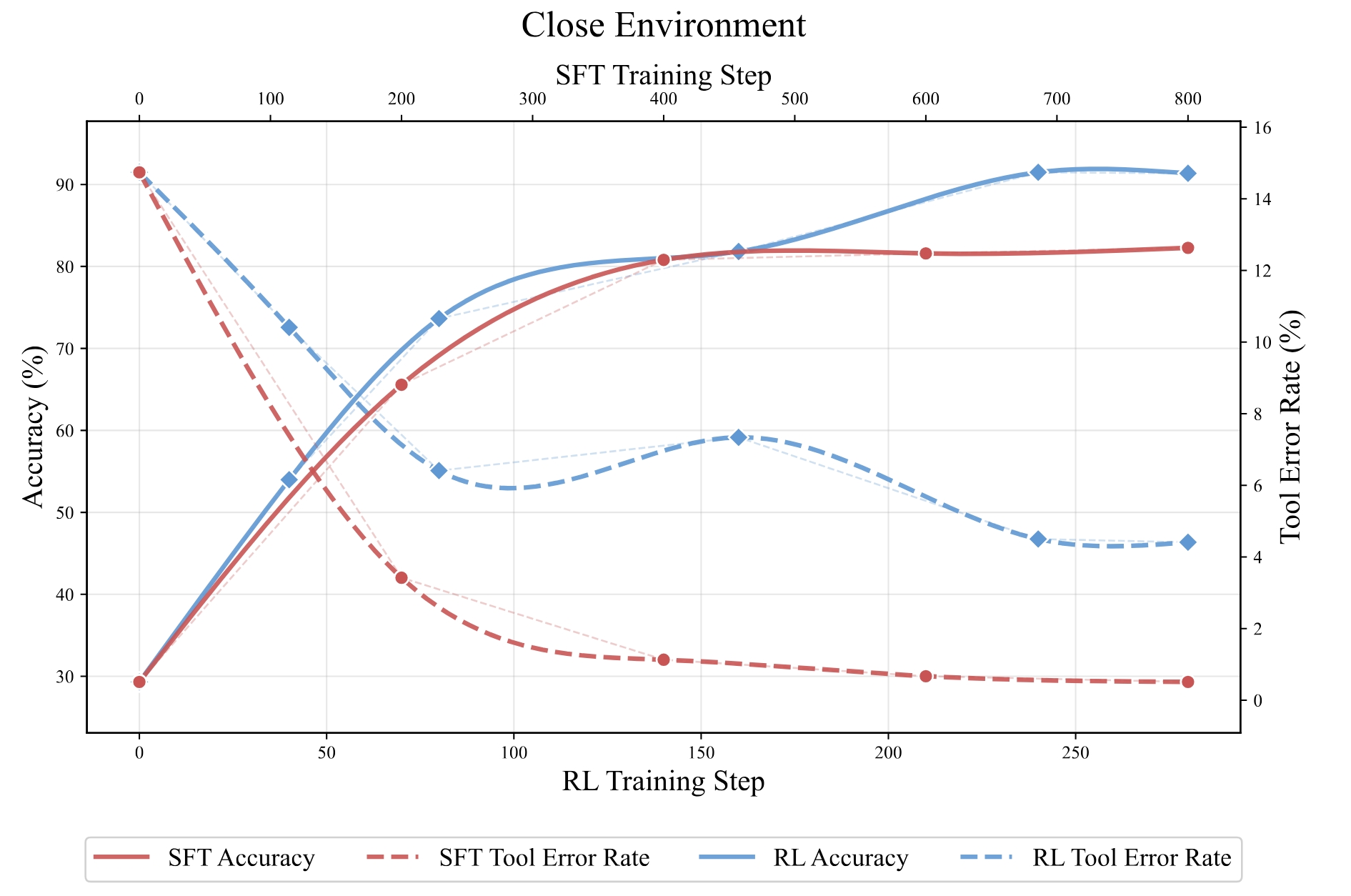
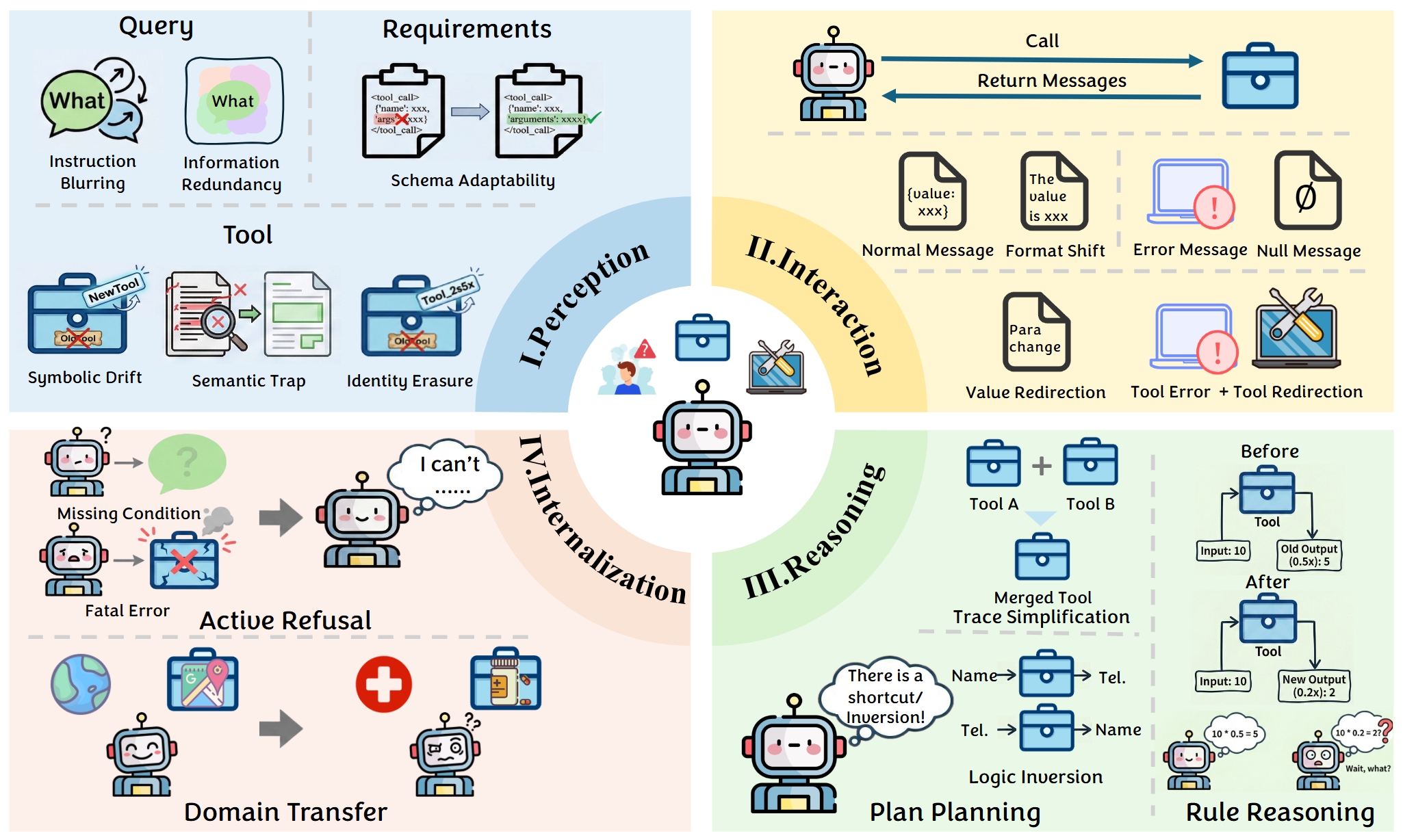
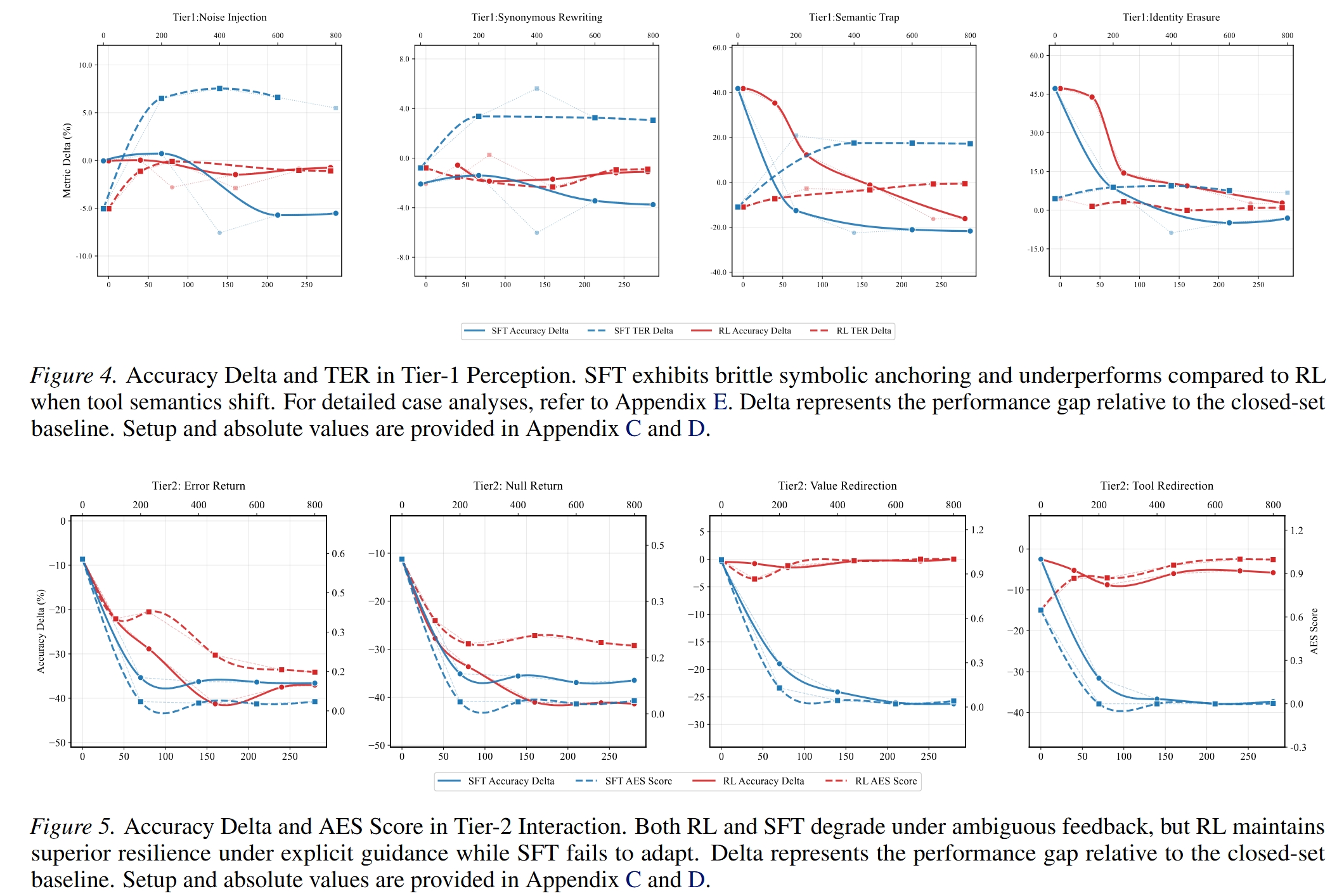
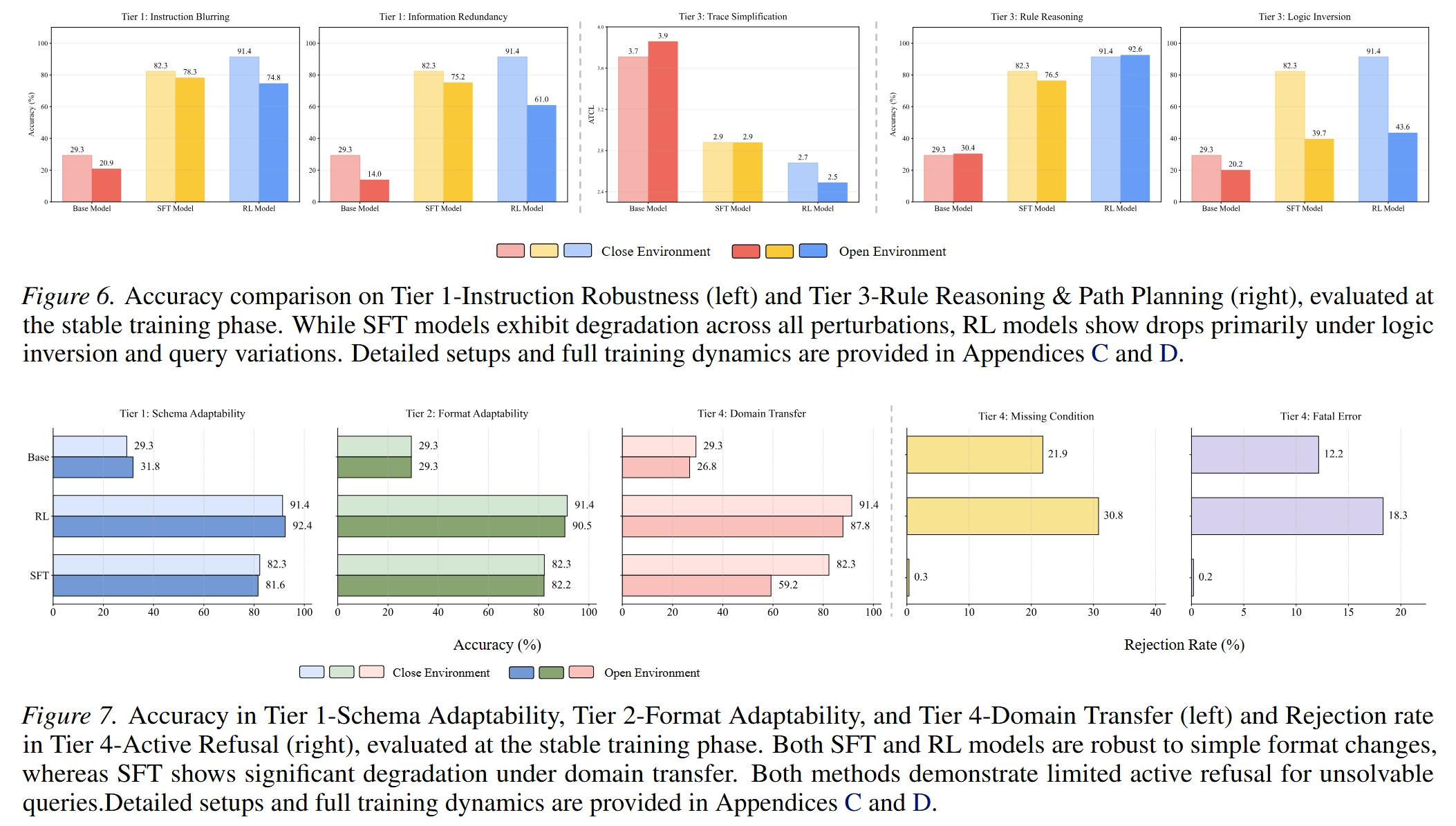
We construct a controlled sandbox environment where we define fine-grained environmental shifts across a four-tier hierarchy, Perception, Interaction, Reasoning, and Internalization, and conduct a comprehensive series of experiments. Our exhaustive analysis yields a series of key insights, demonstrating that agents trained via both Supervised Fine-Tuning and Reinforcement Learning suffer from varying degrees of performance degradation when confronting open environmental shifts.
Building on these insights, we propose Perturbation-Augmented Fine-Tuning (PAFT), a disturbance-based intervention strategy for SFT that lays the foundation for enhancing agent robustness and utility in realistic environments.